关于数据平滑
工作里遇到过两个需要对数据做平滑的 case,因为数据本身特征不同,两次使用了不同的方法。
scipy.signal.medfilt
这份数据量相对比较大,做平滑的目的是从比较杂乱的线条中找到比较明显的趋势。
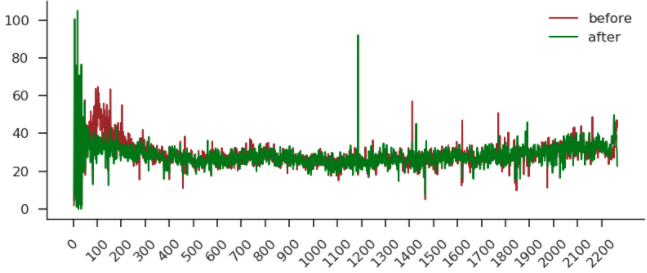
medfilt 顾名思义就是填充中位数(medians filt),以此降低噪声。下图就是平滑后的效果。
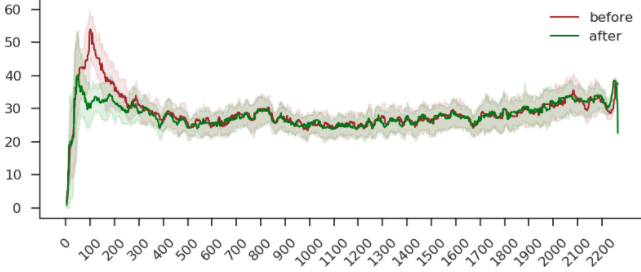
这个方法当时已经满足了 case 的需求。
scipy.signal.savgol_filter
最近在处理的一套新数据,采用 medfilt 就不太合适。这份数据集的数据量噪音大的同时,数据量较小,数据并不连续。

对这个数据集填充中位数进行平滑,导致了出现了如图所示的异常情况。
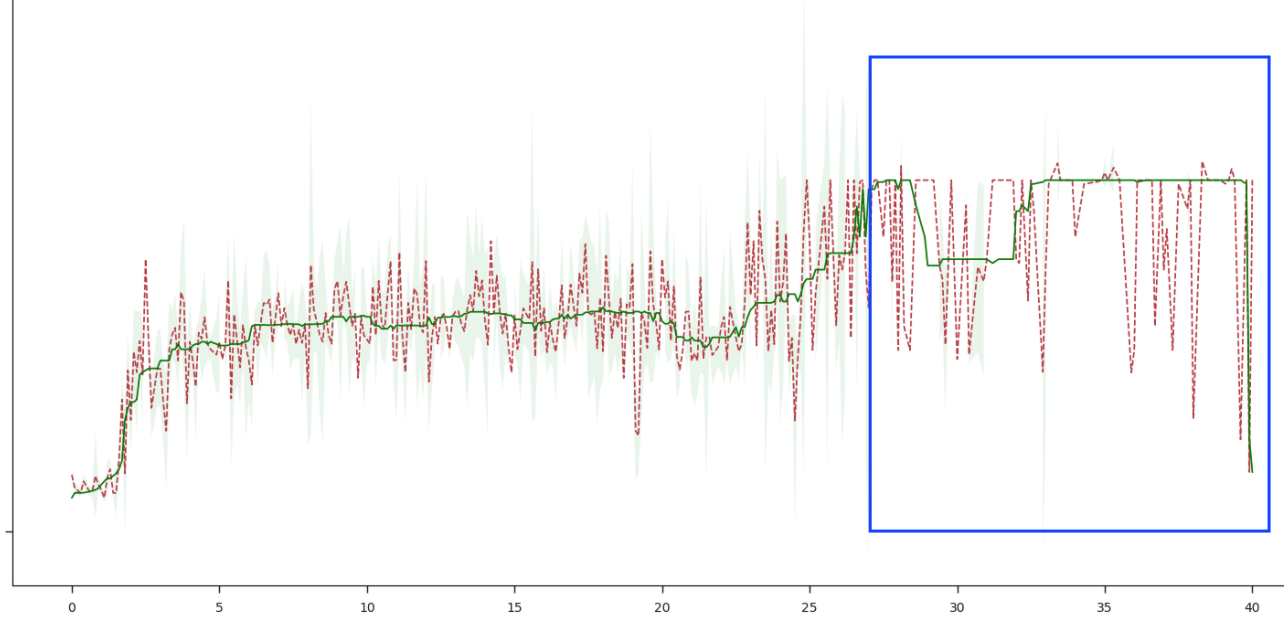
重新思(stack)考(-overflow)了之后,尝试采用卷积平滑的方法。
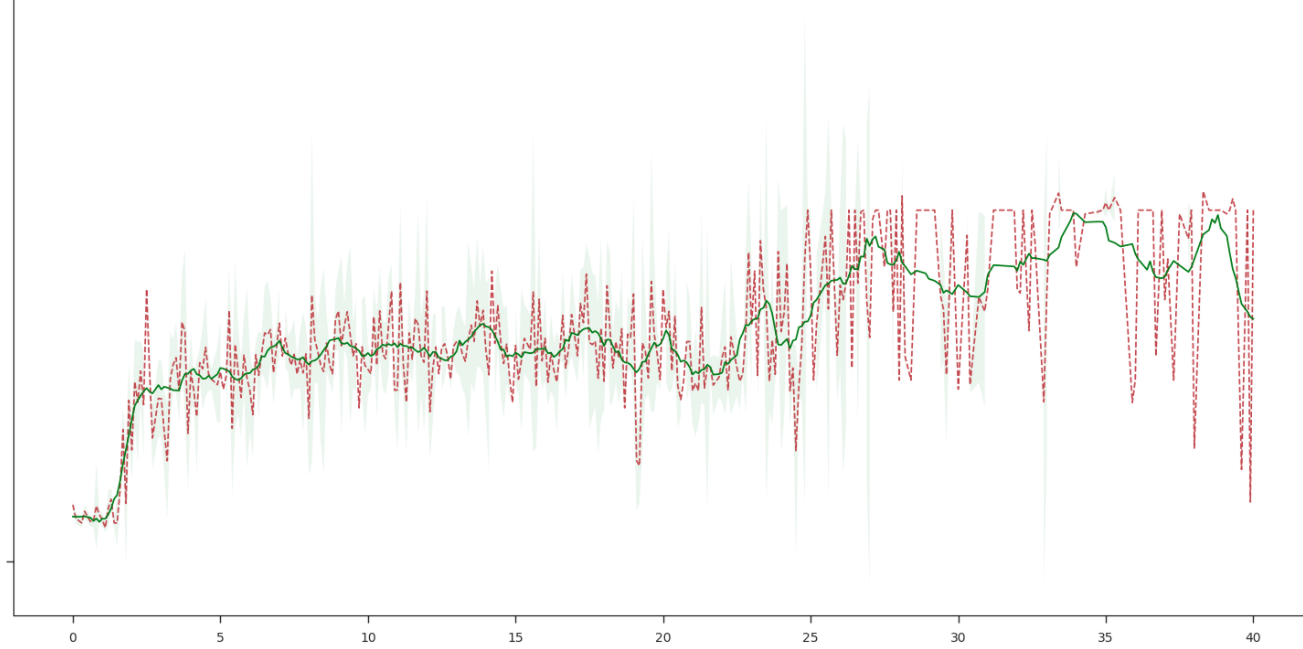
以上两个 case 纯属为了实际项目折腾出来的,其中并没有严谨地去论证最优的 window_length,以及 noise 和 bias 之间的取舍。